
使用python的selenium网页截图踩坑记录
我在使用Python的selenium,调用driver.save_screenshot(url)方法的时候,出现错误,提示是连接请求超时。
实际上是因为一个特殊符号所导致的,"#"就是这个符号。
会被识别成一个标签ID,要使用的时候,可以转换一下,转换成%23 这个编码的就可以了。
最后,记录一下这次踩坑记录。
合成网页代码
def generate_html_preview(data):
content = data["content"]
text = content.replace("\n", "<br>")
imgDataList = json.loads(data['imgDataList'])
html_with_image = ""
if len(imgDataList) > 0:
for i, img in enumerate(imgDataList):
imgHtml = """
<div style="max-width: {width}px;max-height:{height}px;">
<img id="image-id-{index}" style="width: 100%; height: auto; max-width: 100%; object-fit: contain; display: block; margin: auto;" src="data:image/jpeg;base64,{img_str}" />
</div>
"""
html_with_image += imgHtml.format(index=i, img_str=img['url'],width=img['width'],height=img['height']) # Append to html
html_code = f"""
<html>
<head>
<meta charset="UTF-8">
<style>
.content{{
max-width: 800px; /* 修改这个值来设定宽度限制 */
word-wrap: break-word;
overflow-wrap: break-word;
font-size: 35px;
text-align: justify;
line-height: 55px;
}}
</style>
</head>
<body >
<div class="content">{text}</div>
<div >{html_with_image}</div>
</body>
</html>
"""
return html_code
驱动代码
# 全局配置函数
def init_webdriver():
print("配置 WebDriver")
# chromedriver_path = './file/chromedriver.exe'
# service = Service(chromedriver_path)
options = webdriver.ChromeOptions()
options.add_argument("--headless") # 本地运行 建议关闭 无头模式
# options.add_argument('--disable-gpu') # 如果不需要 GPU 硬件加速,可以禁用 GPU
# 确保 ChromeDriver 已经添加到你的 PATH 或指定具体路径
# driver = webdriver.Firefox(service=service, options=options)
driver = webdriver.Chrome( options=options)
# 设置隐式等待时间,例如,等待10秒钟
driver.implicitly_wait(10)
# 设置页面加载超时时间,例如,最多等待30秒
driver.set_page_load_timeout(30)
# 设置脚本超时时间,例如,最多等待30秒
driver.set_script_timeout(30)
return driver
# 只需在代码开始时调用一次
driver = init_webdriver() 最终的合成代码,自适应图片高度,不管多少图片都会自动加上去。
def screenshot(html,data):
print("开始生成图片")
topicId = data["topicId"]
content = data["content"]
imgDataList = json.loads(data['imgDataList'])
# 设置窗口宽度
max_width = 800
# 加载HTML内容
driver.set_window_size(max_width, 800) # 初始高度设置为800,稍后将根据内容调整
driver.get("data:text/html;charset=utf-8," + html) # 这里的html是字符串拼接的HTML,你可以把它替换成你通过Python生成的HTML
wait = WebDriverWait(driver, 30) # 最大时间,网速不好,建议设置60秒以上,如果条件成立,则直接执行不会一定等到60秒后执行
# image_ids = ["image-id-1", "image-id-2", "image-id-3"] # HTML的图片ID比如 <img id="image-id-1" src="http://example.com/image.jpg" /> 跟图片绑定
image_ids = []
for index, img in enumerate(imgDataList):
image_ids.append("image-id-{}".format(index))
try:
for image_id in image_ids:
image_element = wait.until(EC.presence_of_element_located((By.ID, image_id)))
# 使用Selenium执行JavaScript来获取实际内容的高度
content_height = driver.execute_script("return document.body.scrollHeight")
# 根据内容高度设置窗口大小
driver.set_window_size(max_width, content_height)
urlTemp = 'articles/{topicId}.png'
url = urlTemp.format(topicId=str(topicId))
driver.save_screenshot(url)
print("内容生成完成,生成的图片地址在",url)
# 更新数据库值
updateData(topicId,1)
except TimeoutException as e:
print("发生超时异常:", e)
# 这里可以处理异常,例如记录日志或者跳过当前的处理
return
except Exception as e:
print("发生未知异常:", e)
traceback.print_exc() # 打印堆栈跟踪
return最终效果
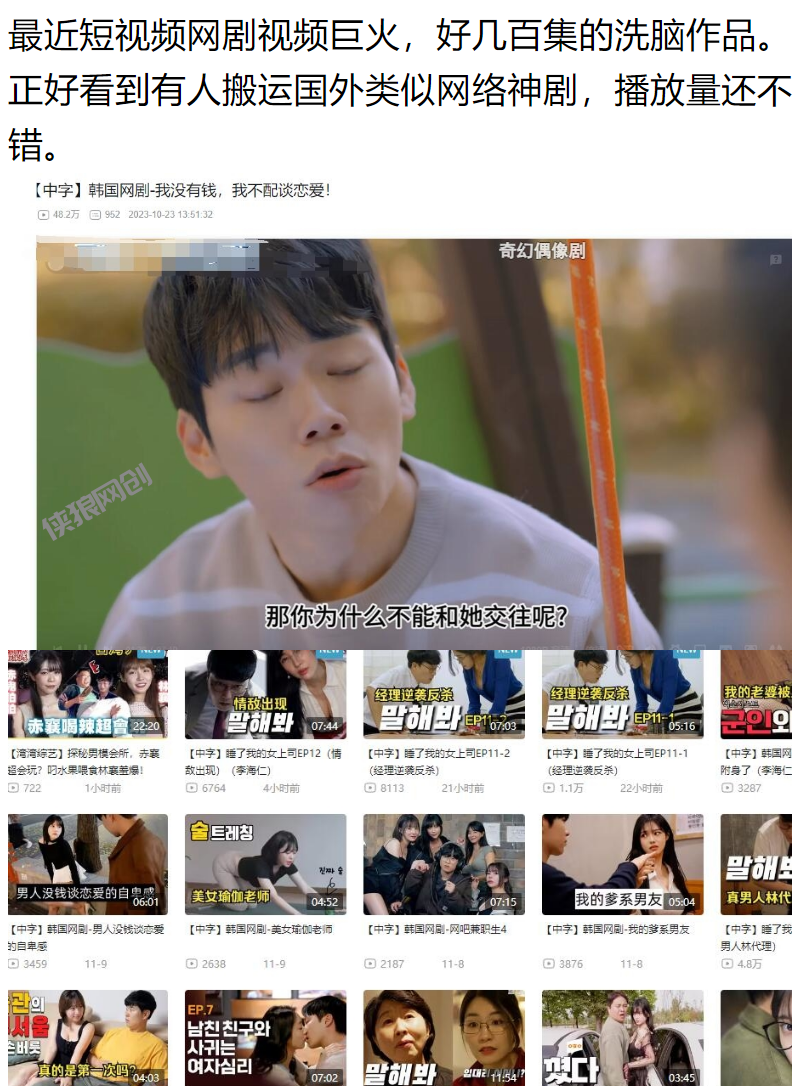
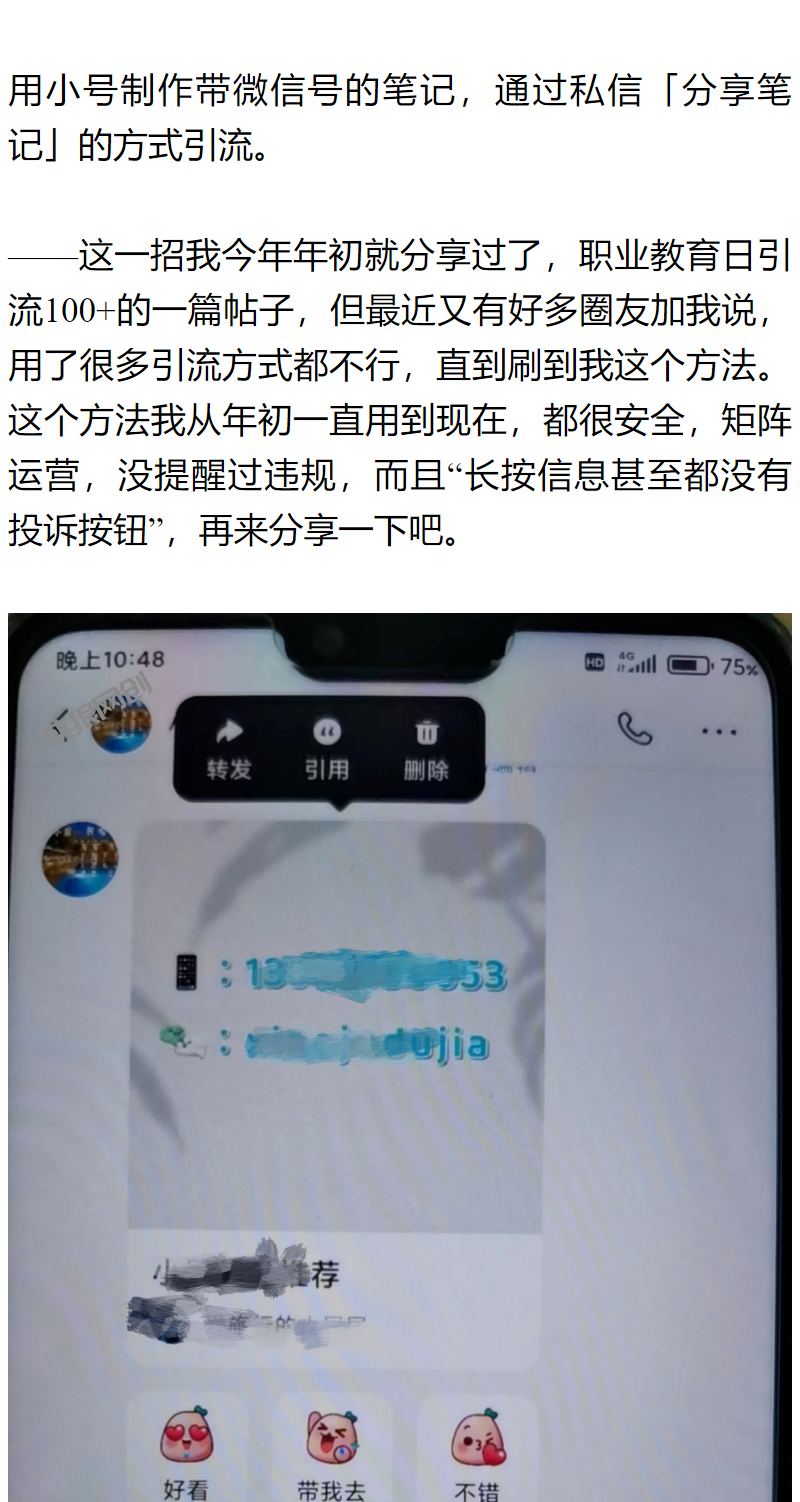

版权声明:
作者:侠狼
链接:https://www.xialangwang.com/1517.html
来源:侠狼网创
文章版权归作者所有,未经允许请勿转载。
THE END
0
二维码
打赏
海报


使用python的selenium网页截图踩坑记录
我在使用Python的selenium,调用driver.save_screenshot(url)方法的时候,出现错误,提示是连接请求超时。
实际上是因为一个特殊符号所导致的,"#"就是这个符……

文章目录
关闭
共有 0 条评论